
How Would You Design Amazon S3?
One of my favorite system design questions from a few years ago and a fascinating thing I learned while answering it.


Intro
I was asked a system design question during an interview a few years ago, and it has remained lodged in my mind ever since. It made me think deeply about how we handle constraints in our software systems and what level of quality constitutes “good enough” for companies of differing philosophies and scales. I hope you find it interesting, too.
NOTE: Check out the other posts from the Concurrency War Stories series here.
Here’s a link to the relevant part of my 2021 Concurrency War Stories talk:
Not all Interview Questions are Equal
About 6 years ago, I did a bunch of interviews before finding my next role. A few of them were all-day interviews where you answer questions for 8 straight hours, minus a break for lunch, but the lunch is usually a vibe check with your potential peers, so it’s not like you can actually relax and enjoy your meal.
During the second half of a full-day interview, I was asked a question that always stuck with me:
How Would You Design Amazon S3?
I walked up to the whiteboard, cracked my knuckles, cleared my throat, said a prayer, and dove in.
Stay Grounded, Start Basic and Evolve
Over the years I’ve learned that this is my best formula for success with interviews:
Start with the simplest possible solution that would work for a heavily constrained situation, such as serving a small number of users with no concurrent operations
One by one, introduce the problems that would cause your solution to become ineffective, and then evolve your design to solve them.
This may sound like common sense, but I spent years using a less consistent approach in which I often dove directly into complex, distributed, highly concurrent solutions. I’d sometimes get lost in outer space and have to desperately descend towards real, palpable problems. I don’t like having to backtrack when solving a problem. I’d prefer to always move forward, and the simpler I start, the easier it is to achieve this.
A Truly Simple Storage Service
So, what would the simplest possible design for Amazon S3 look like?
A single node storing data on disk, right?
Let’s imagine we have 3 clients writing 3 different keys:

I won’t get into the logic of how the node translates a key into a specific disk location. If we’re keeping it simple, you could imagine every key being stored in a separate file.
The Deficiency of Simplicity
This approach has a few problems.
First, If the node crashes, you lose all of your data. Maybe we can solve this by implementing a backup procedure that runs every hour. Worst case you’d lose an hour of data, but that’s better than losing everything. Or maybe we send all writes to a stream, which then sends them… somewhere else. I usually back up my data to S3. Not sure where S3 could backup it’s data to.
Second, if the node crashes, your service becomes completely unavailable. To solve this, maybe we’d run 2 nodes and replicate writes. If you lose both nodes, you’re still in bad shape, but we’re moving in the right direction.
Now, this approach still falls flat from a purely functional perspective if:
You have too much data to store on one node
You have too much traffic to serve from one node
In either of these cases, we need more nodes. So let’s explore that.
Key Mappings
Imagine we still have 3 clients writing 3 keys, but now we have 2 S3 nodes.
To maintain simplicity, let’s assume we’re not replicating data yet. So, both nodes store totally distinct data.
Let’s also assume that you’re using round-robin DNS to route between clients and S3 nodes, so any request can arrive at any node.
So when, for example, a write request for /key1 arrives on node1, should node1 write the key to disk locally, or send it to node2?
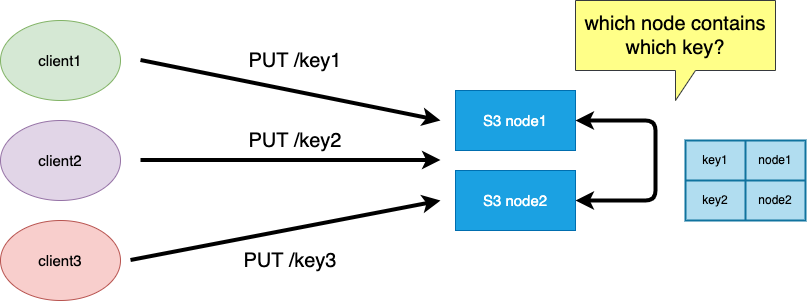
We need a persistent mapping of keys to nodes. Let’s call it a key map. For now, let’s not worry about where and how it’s stored, and just imagine it can be held in memory on each node. Think of an exponentially simpler and worse version of Cassandra’s vnodes.
So, writes arrive, we look up their proper location from the key map, and data is written to the proper location. We’d probably want to scale this to more than 2 nodes, and handle some of the other details I mentioned, but other than that, everything is functional, right?
Correct, I think, except for one thing – where do we write new keys?
A Storage-Based Sticking Point
So if a write arrives for a new key, like key3 in our example, where does it go?
We could randomly choose a node, but what if 2 writes for a new key arrive concurrently?
We could use a distributed lock to ensure that only one write for a given new key could proceed at a time, but that seems too expensive.
I got stuck here for awhile. Here’s a summary of the exchange between my interviewer and I:
Interviewer: You’re thinking too hard.
Me: We could randomly choose a node, but different nodes could be chosen on concurrent writes. We could randomly designate one node as the place for new keys, but I think that would distribute the load in a strange way, plus you’d probably need to rotate the “new keys” node from time to time and that would require coordination.
Interviewer: You’re still thinking too much like a systems engineer. Let’s simplify: what’s the fastest way to choose a node to write a new key to?
Me: Randomly choose a node.
Interviewer: Right. So why not do that?
Me: On a concurrent write for a new key, the data could be written to multiple random nodes.
Interviewer: Right. But let’s pretend randomly choosing a node for the write was your only option. How could you resolve that?
Me: Do some type of cleanup after the write?
Interviewer: Exactly. This is why S3 is eventually consistent. There’s a cleanup job that runs every few minutes and assigns each key with conflicting locations to a single, correct location. In the time period between a write and the cleanup, reads can be inconsistent because you may be reading from multiple wrong locations.
Me: Fascinating.

Learn how to build high-volume systems with massive impact in my new book Push to Prod or Die Trying.
Building in a Real and Constrained World
Note that S3 became strongly consistent in 2020, so the point about eventual consistency hasn’t been true for years. But also, I’m not certain it was ever true. My interviewer used to work at Amazon, but people say lots of things with varying degrees of truth and accuracy.
True or not, it fits a pattern I’ve seen in my work over the years, so I’m incentivized to believe it. When you design a system to work in the real world, it is going to have lots of dark and ugly corners. They fill the space between a constrained, unfriendly world and our desire to add value within it.
In my experience, the ability to surface constraints, optimally balance a solution between them, and then ship something into production is what elevates the best engineers from the crowd.
Companies that empower these engineers are able to move quickly and build great things, like S3. Companies that instead choose to slowly build consensus for foolproof and future-proof solutions build mediocre things, stagnate, and die.
For mortals, there is no creation without constraints. There is a lot of space between greatness and stagnation. When in doubt, push the damn thing into production.
Most of us are not building at the scale of S3, so their system requirements are generally more demanding than the rest of us. However, unless you’re building software for banks, medical equipment, navigation systems, military defense, or other domains involving literal or figurative life and death – if something as flawed as eventual consistency is good enough for Amazon, shouldn’t it be good enough for you, too?
Have a wonderful day.