


How We Built a Self-Healing System to Survive a Terrifying Concurrency Bug At Netflix
Our CPUs were dying, the bug was temporarily un-fixable, and we had no viable path forward. Here's how we managed to survive.


Intro
NOTE: Check out the other posts from the Concurrency War Stories series here.
Hello friends. Today, I’m discussing one of my favorite production incidents from my time at Netflix.
Here’s an overview:
A concurrency bug was killing our CPUs
It was Friday afternoon
Rolling back was cumbersome
We couldn’t achieve a true fix until Monday
How could we possibly prevail?
Here’s a link to the part of my 2021 Concurrency War Stories talk where I discuss it:
When Clients Become Servers
During my time at Netflix, there was an effort to redesign the Netflix API from a REST-ish thing to an RPC-ish thing. The idea was that client teams would write their own endpoint scripts to deploy on the server in order to enable more flexible and efficient interactions.
By “client teams,” I mean the teams building the Netflix app that ran on mobile devices, game systems, TVs, and so on.
Here’s a picture from the blog post I linked:

I had zero involvement in this project, other than attending a few architecture meetings and nodding my head during hallway conversations.
CPU Carnage
It was a Friday afternoon, and I heard a lot of commotion. I emerged from my cubicle to see my colleagues passionately discussing a problem: our CPU usage was slowly growing across our cluster.
After looking at a bunch of graphs and some, you guessed it, JVM thread dumps - we discovered that our CPU usage was growing due to a concurrency bug in an internal library used by the client scripts that ran in our cluster.
Somewhere under the hood, they were using a HashMap instead of a ConcurrentHashMap, and to my memory, some calls to HashMap.get() seemed to be running infinitely.
Infinitely running code means that the CPU running that code is completely consumed until you kill the process.
In other words: gradually, one by one, we were losing all of our CPUs.
The impact was slow but severe. The numbers were something similar to this:
We were losing 1 CPU every 2 minutes = 30 CPUs per hour
With 8 CPUs per instance, we were losing ~4 instances of capacity per hour
Every 24 hours, we were losing ~96 instances of capacity
Further:
If we autoscaled every day from 500 at trough to 1000 instances at peak…
After 24 hours, we’d have lost roughly:
~10% (96/1000) of peak capacity
~20% (96/500) of trough capacity
(Note that our capacity loss projection for the trough was likely incorrect. Check out the graphs a few sections later for details.)
We had to do something before the end of the day. We iterated through our options:
Could the responsible client team fix the bug?
Yes, but they’d need some time and wouldn’t be ready until Monday.
Could we roll back?
Not easily. I can’t recall why.
Could we somehow detect the problem and reboot the relevant server(s)?
Not easily.
The path forward was unclear.
The Inflection Point
This was an inflection point at which many other places I’ve worked would have psychologically collapsed under the weight of their own worldview. In other words, some companies have a culture that enables engineers to minimize the unpleasantness of situations like this, while others have a culture that amplifies the unpleasantness to the maximum possible value.
Examples of suboptimal approaches I’ve seen in similar situations:
Manager1 pressures Manager2 to force their team to work through the weekend until the bug is fixed.
Our on-call engineer manually reboots servers all weekend long.
Maybe the primary and backup on-call work in shifts so that the primary can still sleep and eat.
If it’s too much work for the on-calls, draft a small “task force” to perform the manual work until the problem is resolved.
While we’re at it, let’s have status calls every 4 hours to keep all stakeholders informed.
These approaches all suck, but I’ll concede that they may be the best possible option in specific contexts.
I’ll say this about Netflix – during my time there, I always found it to be an extremely practical place. To give an example: the API redesign I mentioned at the start of the post was a bit of a crazy idea at the time. Moving away from REST in the year 2011 felt like insanity, at a glance. But if you glanced a bit longer until it became a stare, you’d realize that this crazy idea was a perfectly fitted solution to one of our biggest problems.
Practical engineering can mean many things, but a definition I often return to is: having clear goals and making choices that are aligned with them.
So, thinking practically, what were our goals for this CPU situation? To fix the bug, of course. But it was Friday, and that wasn’t possible until Monday.
What would be a viable second-best goal?
The Worst Self-Healing System Ever Created
An ideal second-best solution would be to automate cluster maintenance so that we could all enjoy our weekend with no manual interventions.
The dream of every engineer who has ever been paged in the middle of the night: a self-healing system.
Here’s how we did it:
We pinned our cluster size to the max of our autoscaling group. In other words, we turned off autoscaling and resized our cluster to meet our max capacity.
We created a rule in our central monitoring and alerting system to randomly kill a few instances every 15 minutes. Every killed instance would be replaced with a healthy, fresh one.
Why not just reboot them? Terminating was faster.
It worked perfectly. We all had a relaxing weekend as our cluster saw many CPUs die and many others reborn in their place.
Interlude of Graphs
I attempted to reproduce this situation using a graphing library I’m building that allows me to functionally generate synthetic data. Let’s look at a few results.
I modeled the situation with bad instances (aka servers, VMs, or containers, in this context) instead of CPUs, since it’s easier to think about. Here’s a graph showing:
a linear autoscaling approach
a trough time of 4am
a peak time of 8pm
min and max cluster sizes of 100 and 1000, respectively
each instance having a 1% probability of failure every hour
This didn’t look like I expected. To my memory, we were more concerned about our degraded capacity during the trough rather than the peak. But according to this graph, as we scale down our cluster, we scale down both good and bad instances proportionately. So the bigger problem was at peak, when we had the max number of bad instances, since they had been growing since the previous trough.
Here’s a graph of capacity (“fraction of expected capacity" = good instances divided by total instances) over the same period:
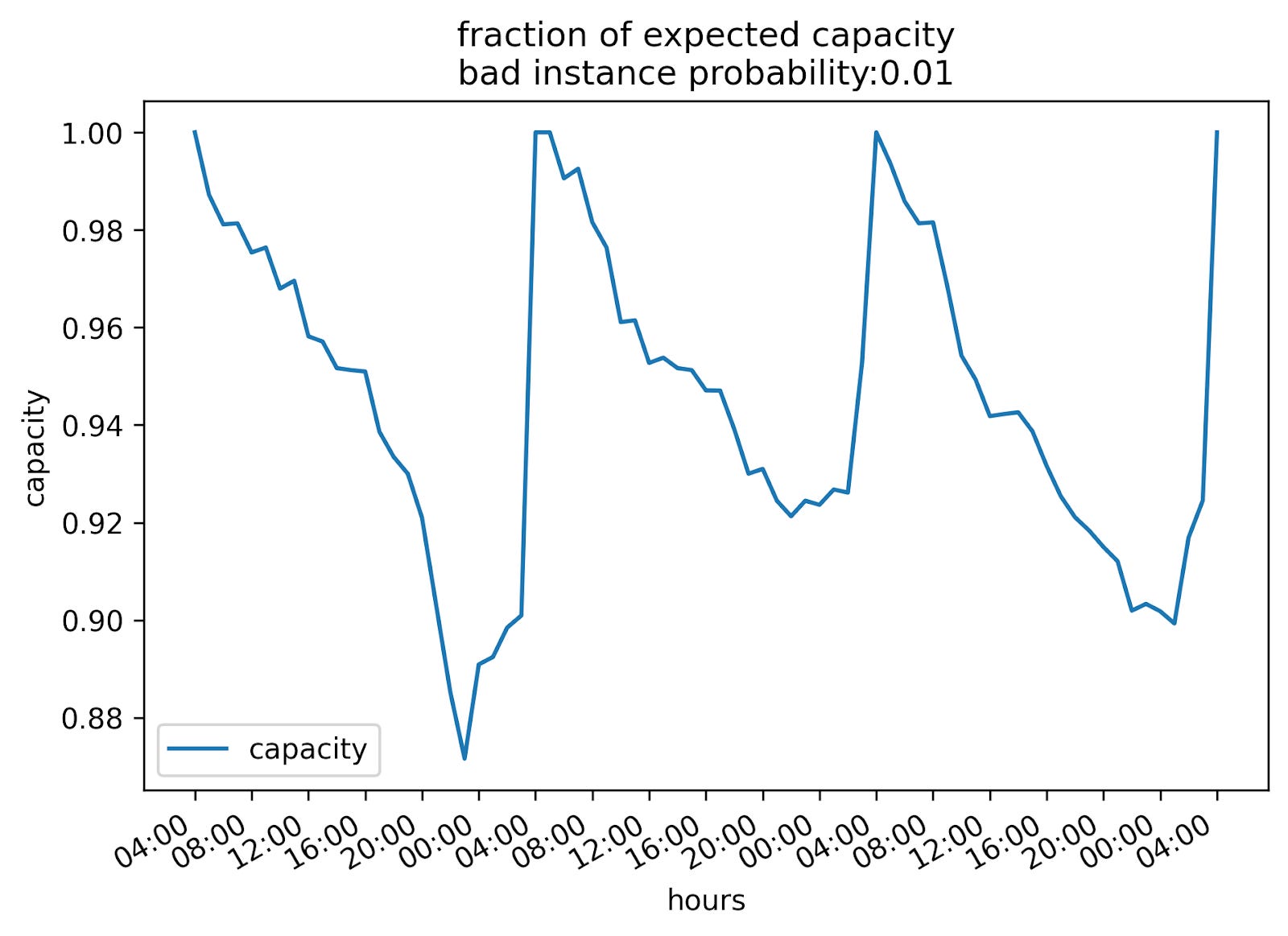
The time period starts at the trough, where you can see that our capacity is close to 100%, as opposed to peak where it drops to around 90%. Generally, 90% sounds good, but in the context of capacity, if you only have 90% of what you think you have, it’s a problem.
I also modeled our solution, which was to pin our cluster to the max instance count, disable autoscaling, and automatically terminate instances at some cadence. For this example:
the probability of an instance failing each hour is still 1%,
we terminate a random 5% of our cluster every hour
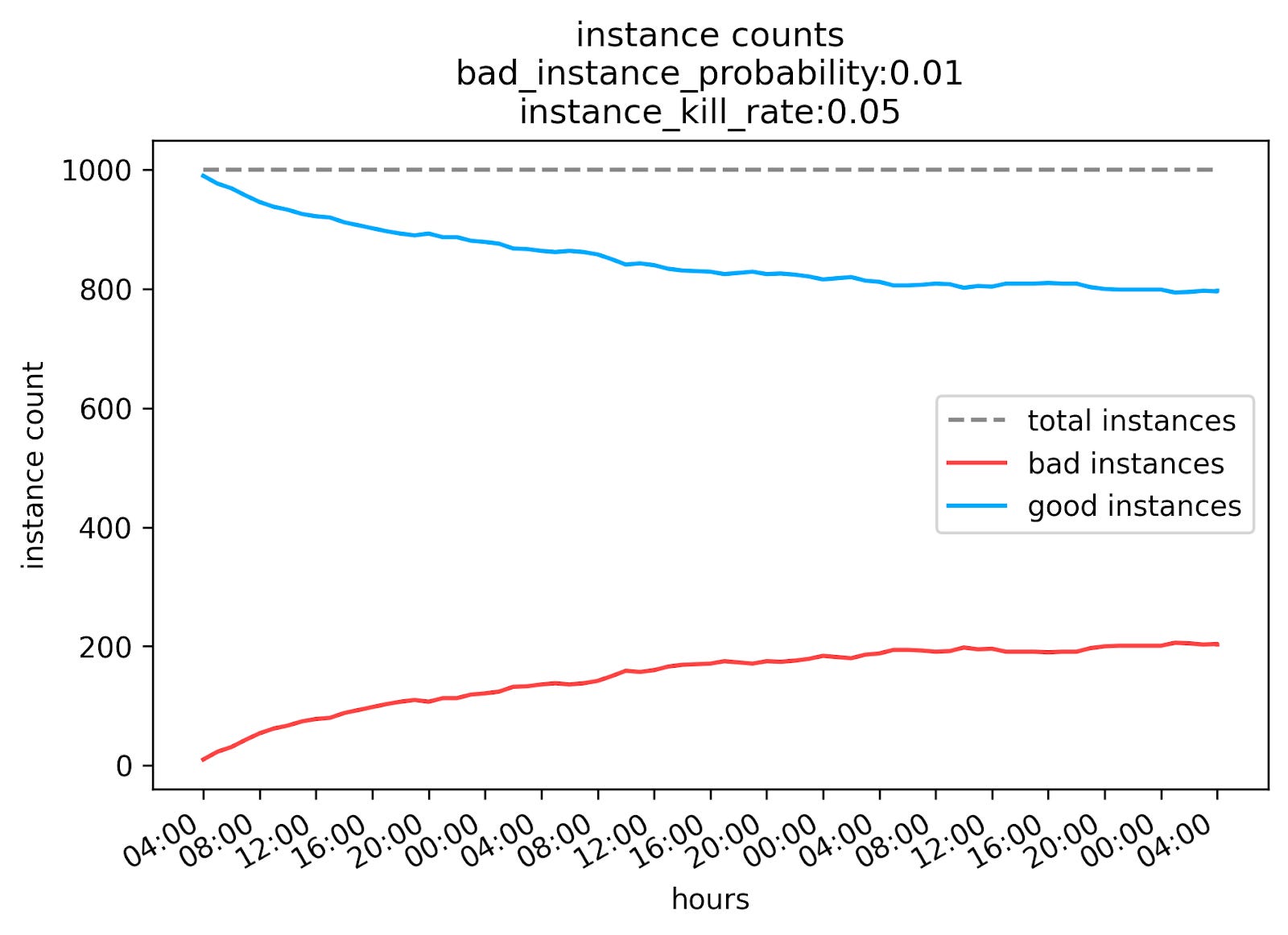
You can see that we converge at around 800 healthy instances over time.
Here’s a graph of capacity over the same period:
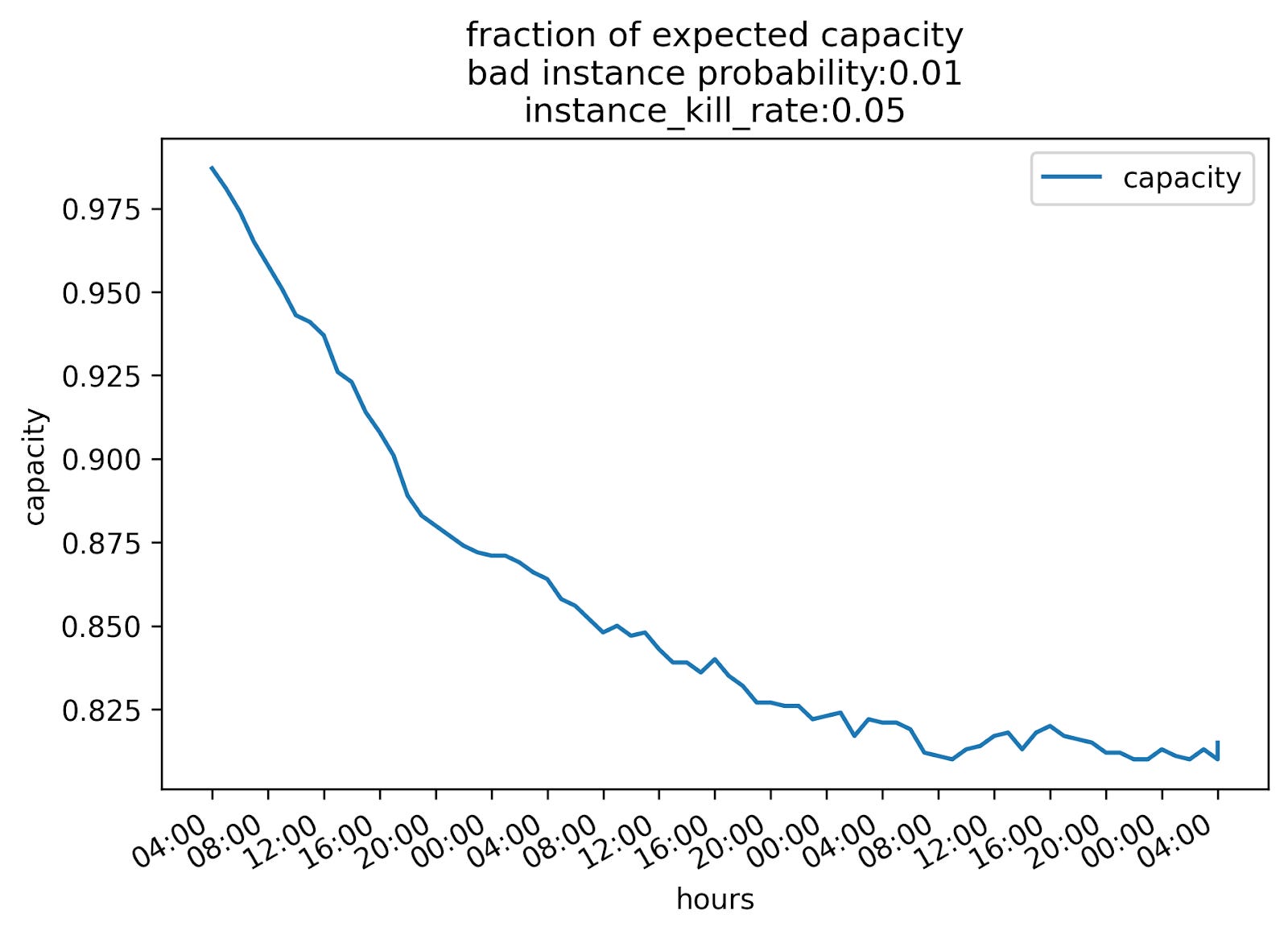
Capacity converges around 80%, which isn’t ideal, but you could pin your cluster to a higher-than-normal max to achieve your desired healthy instance count.
It was interesting to plug in different values for failure rate and instance kill rate and observe the effects. I’ll dive into that in a future post since this one is already too long. For now, let’s return to our main narrative.
If you enjoy this post, check out the early release of my new book Push to Prod or Die Trying.
It’s about building high-volume systems, thriving through sociotechnical challenges, managing operational chaos, and surviving gruesome production incidents.

Technological Adulthood
On Monday, the client team deployed their fix. We disabled our auto-terminate rule, re-enabled autoscaling, and moved on with our lives.
I’ve always loved this incident for a few reasons:
This was a rare but brutal example of how writing non-thread-safe code can cripple your systems. There are a lot of problems you haven’t seen before because you’re not working on systems with sufficient volume to generate them.
The solution of automatically terminating random instances felt like a terrible engineering practice. But in the moment, it was the perfect solution to our problem.
Most importantly, we prioritized our own sanity.
Incidents come in many colors and shapes, so our solutions must reflect that variety to be maximally effective.
The best teams I’ve worked on have used the most unconventional techniques, and I don’t think that is a coincidence. This is technological adulthood: having the courage, confidence, and clarity to use unconventional or suboptimal techniques to pursue your goals.
In a sociotechnical system, you can use engineering principles to optimize for things other than latency, throughput, or uptime. You can also build solutions that optimize quality of life, and this is one of my favorite examples.
I really enjoyed reading about how you handled the issue with autoscaling and instance termination. The reflection on technological adulthood really stood out to me, it’s something you only fully appreciate after facing real-world challenges. Great post!